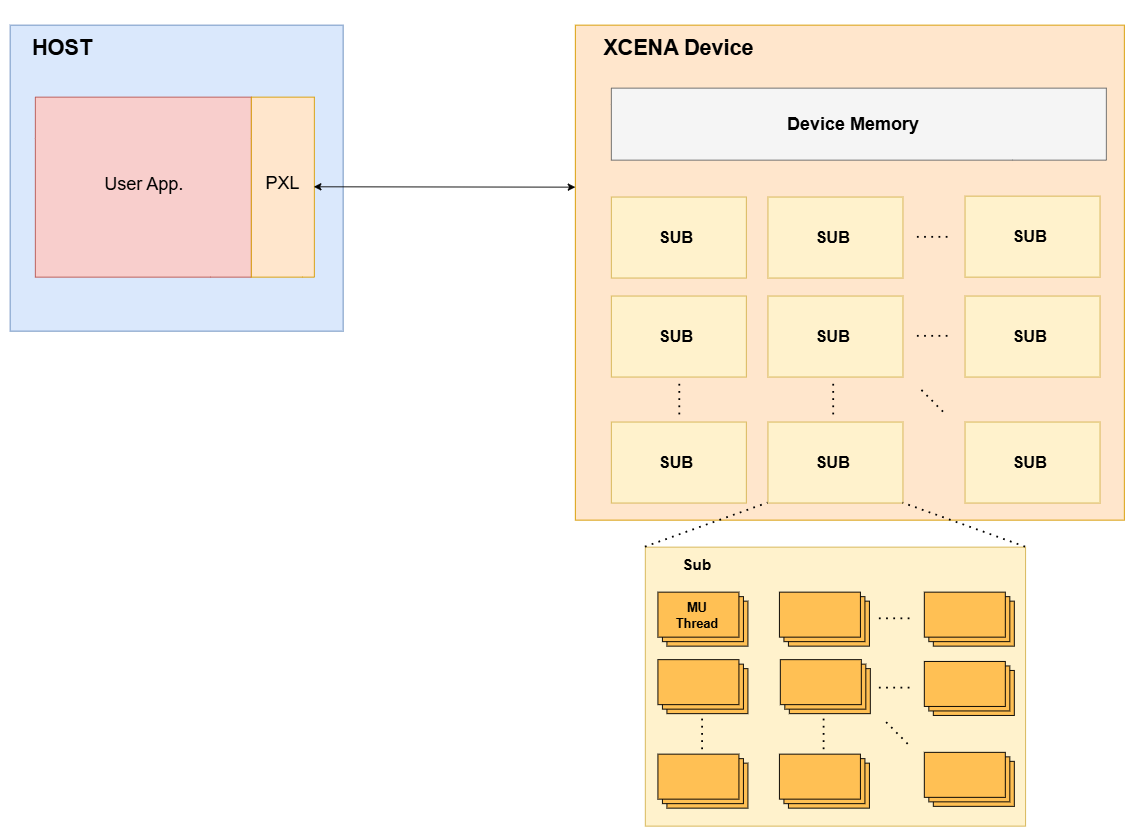
Parallel Xceleration Library (PXL)
PXL is the core runtime library for XCENA SDK. It provides APIs to manage device resources, load compute kernels, and execute parallel operations on XCENA hardware.
Development Workflow
XCENA SDK enables offloading computation to CXL memory accelerators:
flowchart TD
subgraph PrepareOffloading[Prepare Offloading]
direction LR
OffloadingApplication[Offloading Application] --> |Build|ComputeKernel[Compute Kernel]
end
subgraph Accelerator
direction LR
Processor <--> |Process Kernel|CxlMemory[CXL Memory]
end
PrepareOffloading ==> |Load| HostApplication[Host Application]
HostApplication <--> |API Call| RuntimeLibrary[Runtime Library]
RuntimeLibrary <--> |Control| Processor
RuntimeLibrary <--> |Allocate| CxlMemory
HostApplication <--> |Data Access| CxlMemory
Development Steps:
- Write Compute Kernel (MU code)
- Write Host Application (PXL API)
- Build both components
- Execute on hardware or emulator
Core Capabilities
Resource Management:
- Allocate/free device memory
- Allocate/free compute resources
- Query available resources
Kernel Execution:
- Load compiled kernel binaries
- Launch parallel operations
- Synchronize execution
Kernel Programming Basics
Before using PXL APIs, understand MU kernel development fundamentals.
Essential Requirements
Include Header:
#include "mu/mu.hpp"
Register Host-Callable Functions:
void my_kernel(int* data, int size) {
// Kernel code
}
MU_KERNEL_ADD(my_kernel); // Required for host to call this function
Constraints
- Parameters: Maximum 9 parameters per kernel function
- Heap Size: 3MB limit
- Stack Size: 64KB limit
Getting Task Index
For pointer-based execution, use mu::getTaskIdx():
void parallel_kernel(int* data, int size) {
uint32_t taskIdx = mu::getTaskIdx();
int offset = taskIdx * size;
// Process data[offset...offset+size]
}
PXL Overview
Please refer to PXL C++ API docs for more details. 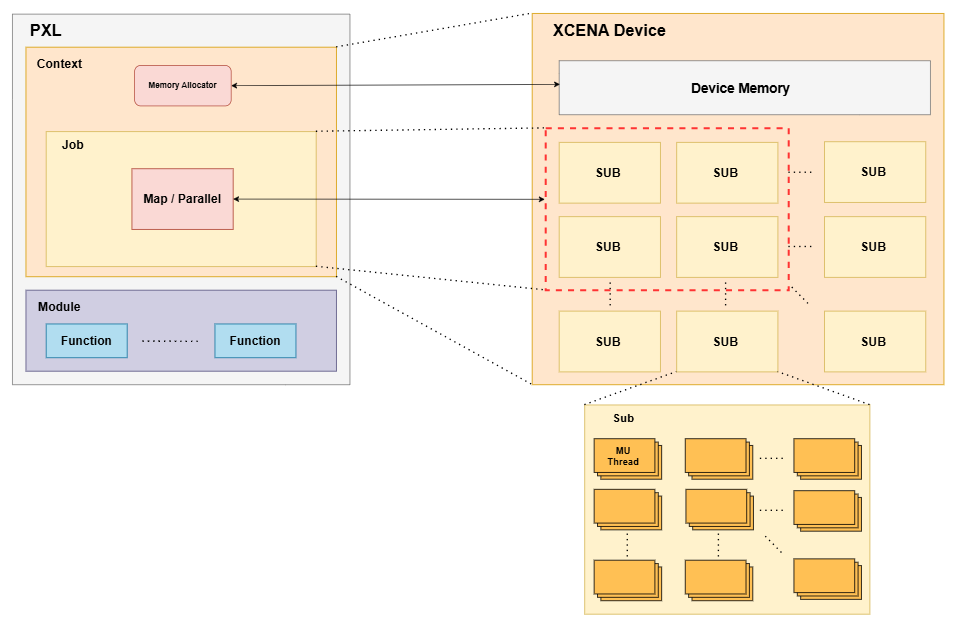
Context
A Context manages device memory resources and holds overall information about the device.
- Allocate / Free device memory resources.
auto ptr = context->memAlloc(size); context->memFree(ptr); - Check device resources
printf("Remain memory in device %d = %d\n", deviceId, context->remainMemorySize()); printf("Remain sub in device %d = %d\n", deviceId, context->remainSub()); - Allocate / Free device compute resources by creating
Job.auto numSub = 4; auto job = context->createJob(numSub);
Job
The Job manages device compute resources and offloads user applications to the device. A Job is composed of one or more Sub units, which are the fundamental compute resources on XCENA devices for executing user applications.
- Load a binary file into the device.
const char* filename = "mu_kernel.mubin"; auto muModule = pxl::createModule(filename); job->load(muModule); - Allocate / Free device compute resources.
// allocates additional Sub to current job. auto numSub = 2; auto ret = job->subAlloc(numSub); // return false if there is no remaining sub to assign current job. - Create
Map.auto testCount = 1024 * 1024; auto muFunc = muModule->createFunction("mu_main"); // name of mu_kernel main. auto map = job->buildMap(muFunc, testCount);
Map
The Map is responsible for executing a map operation on a given job. It provides methods to set input and output arguments, set the batch size, and synchronize the execution. The map operation can be executed by calling the execute method.
map->execute(...) takes up to 10 arguments, which should be a C++ fundamental type, a device memory pointer allocated from the Context, or a NDArray.
There are two main ways to launch operations with Map:
-
Launch with NDArray: The
NDArraydefines the type and shape of the array so thatMapcan appropriately distribute array elements to each MU. TheMapoperation divides the array argument into equal chunks and distributes the sliced chunks to the MU threads.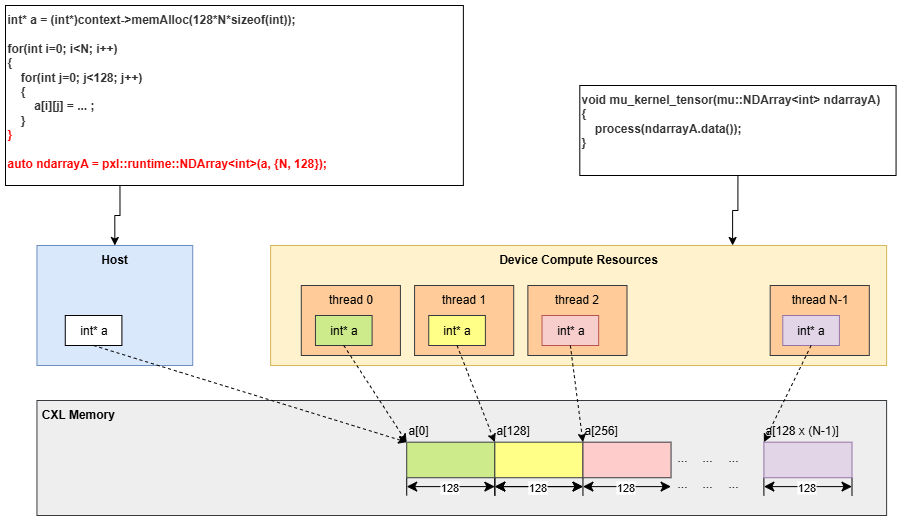
-
Launch with Pointer: When using a device memory pointer or C++ fundamental type, these arguments are distributed identically to all MU threads belongs to assigned Sub. In MU kernel code, the user needs to reference the appropriate memory address with
taskIdx, obtained by callingmu::getTaskIdx()function.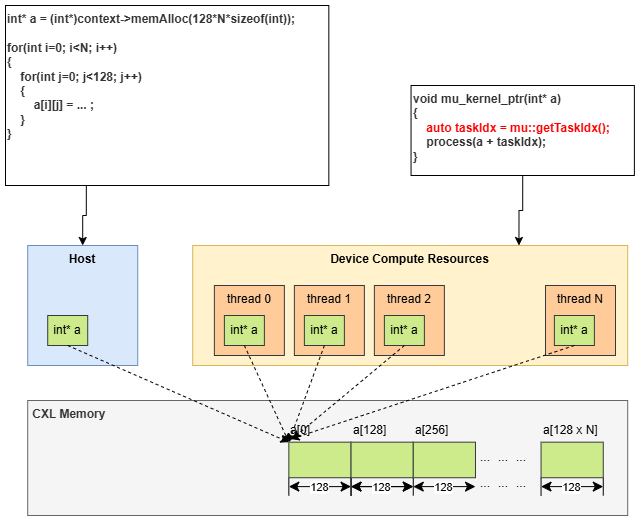
Module and Function
The Module represents MU kernel binary compiled by provided MU compiler. The Function points to the starting function when the user launches offloading job on the device. The Module provides an interface for accessing functions within a module. It also provides information about the module’s binary path and the number of functions it contains.
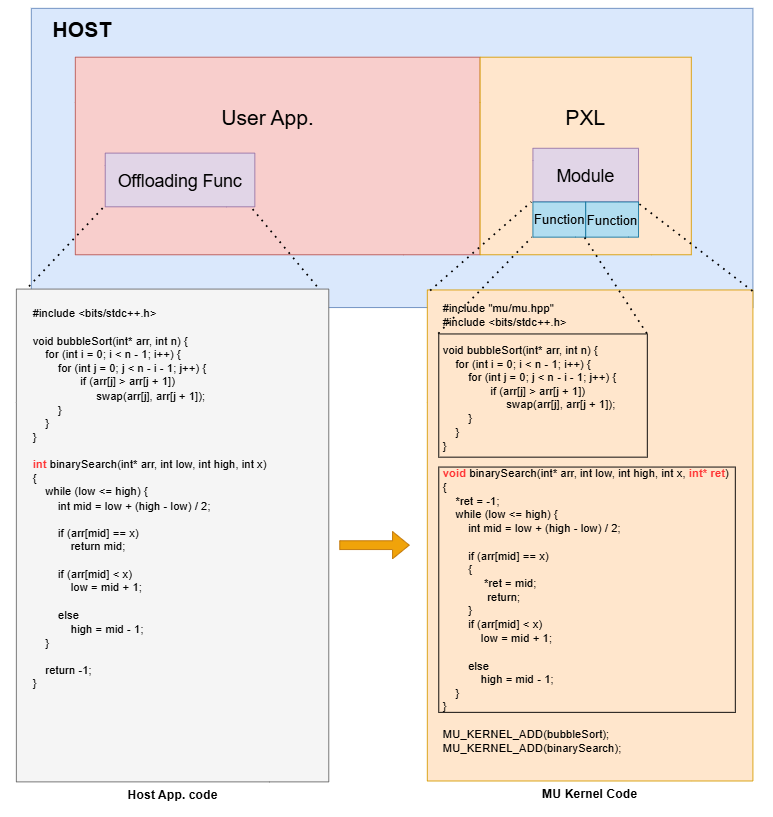
const char* filename = "mu_kernel.mubin";
auto muModule = pxl::createModule(filename);
auto sortFunc = muModule->createFunction("bubbleSort");
auto searchFunc = muModule->createFunction("binarySearch");